Motivation (2)

-
HTML im Browser
-
Daten für Perl freilegen
-
Navigation (WWW::Mechanize)
-
Extraktion (Web::Scraper)
Web::Scraper
Web::Scraper
-
Geschrieben von Tatsuhiko Miyagawa

-
Plagger (RSS-Anwendung)
-
Angelehnt an Ruby's
scrapi-Modul
Die Webseite

-
Beispiel:
-
Extraktion aus Kinoprogramm
Die Webseite
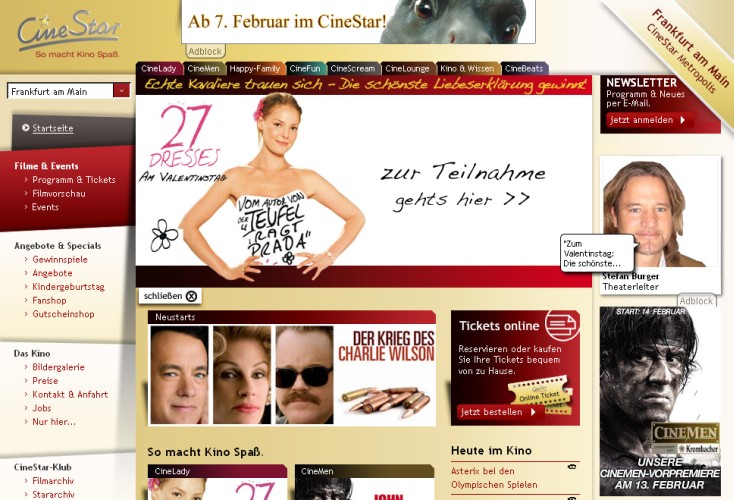
Echte Webseite
Die Webseite
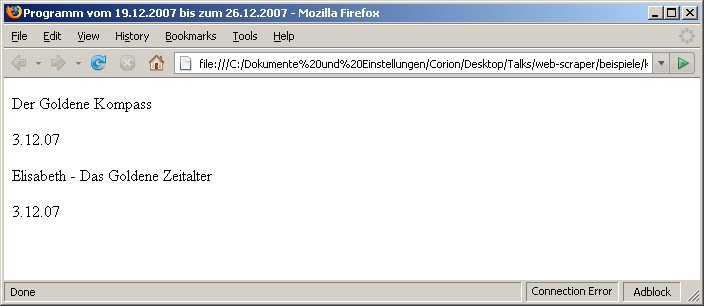
Vereinfachte Webseite
Die Webseite
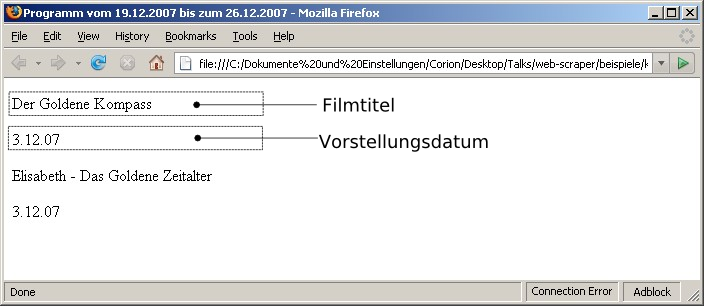
Vereinfachte Webseite
Zielelemente
Die Webseite (HTML)

Die Zielelemente (HTML)

CSS Selektoren und HTML Tagnamen

CSS Selektoren und HTML Tagnamen

CSS Selektoren und HTML Tagnamen

CSS Selektoren und HTML Tagnamen

Beispiel f. mehrere Elemente

Beispiel f. mehrere Elemente
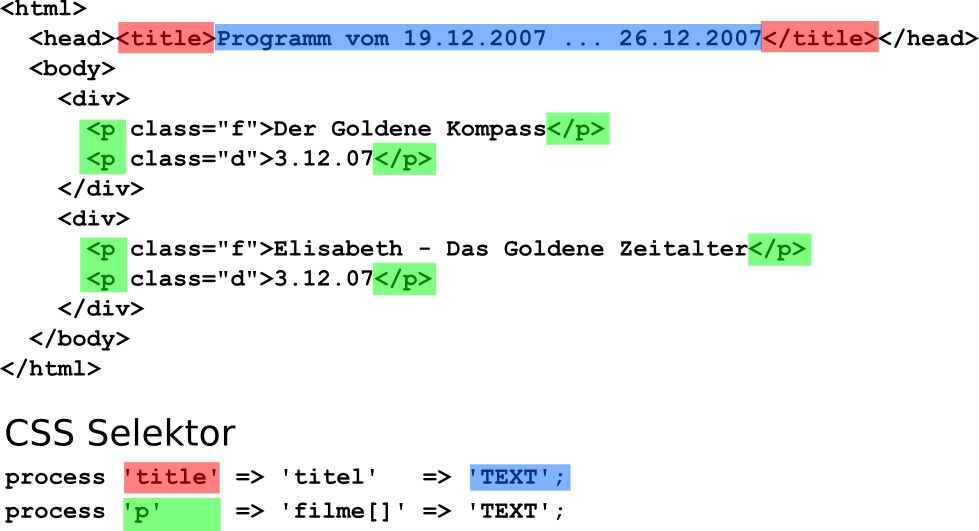
Beispiel f. mehrere Elemente

Beispiel Klassenattribut

Beispiel Klassenattribut
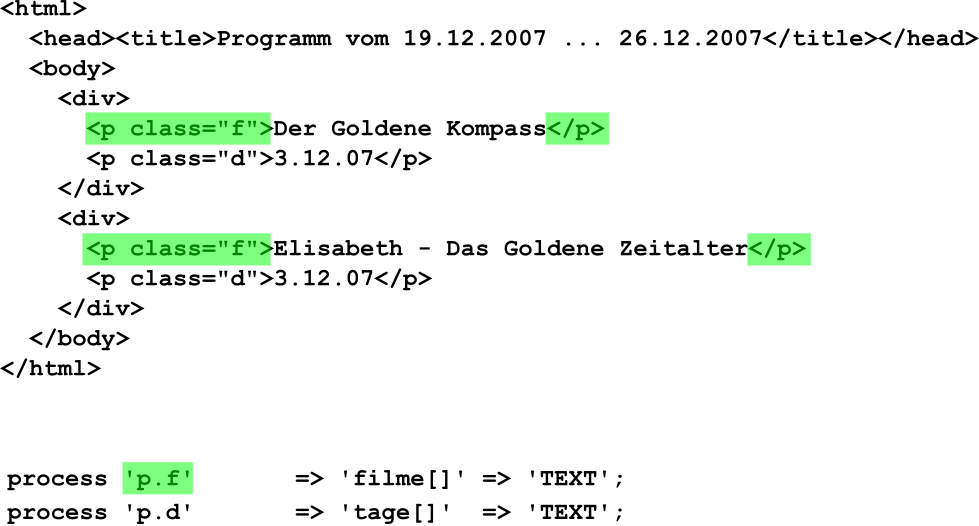
Beispiel Klassenattribut
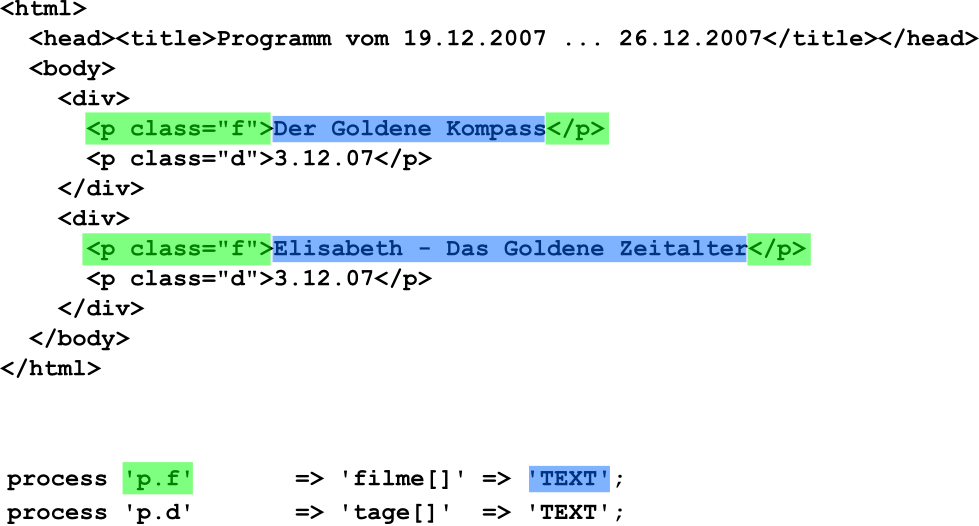
Beispiel Klassenattribut
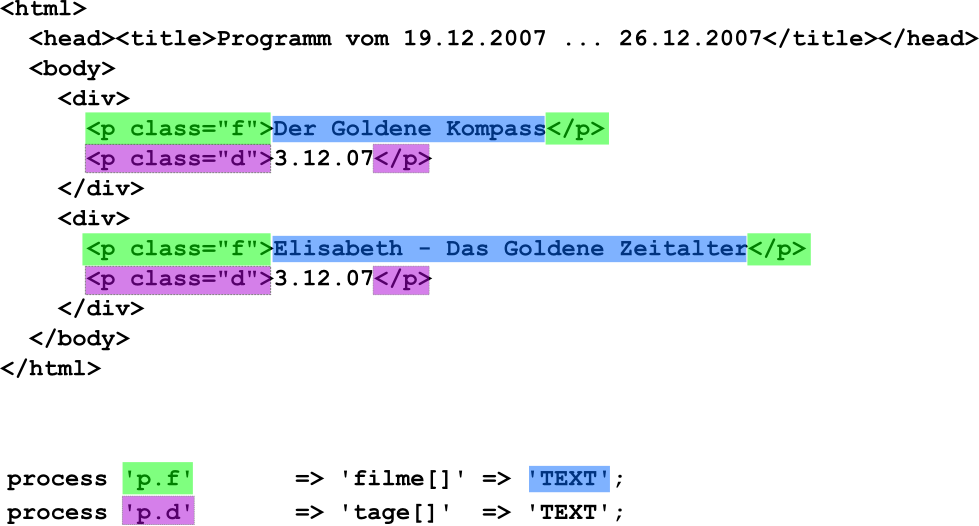
Beispiel Klassenattribut

Andere Beispiele

Andere Beispiele

Andere Beispiele

Andere Beispiele

Zusammenfassung CSS Selektoren
CSS Selektoren

-
... finden HTML Elemente
-
... in einfacher Hierarchie
-
Wenige Attribute (
class,id)
XPath

Falls CSS nicht genug ist
Zusammenfassung XPath Selektoren
XPath Selektoren
-
... finden HTML Elemente
-
... in komplexer Hierarchie
-
Alle Attribute (
@class) -
Komplexe Prädikate (
div/[p@f]) -
Komplexe Abfragesprache
Schleifen mit Web::Scraper

Schleifen mit Web::Scraper

Schleifen mit Web::Scraper
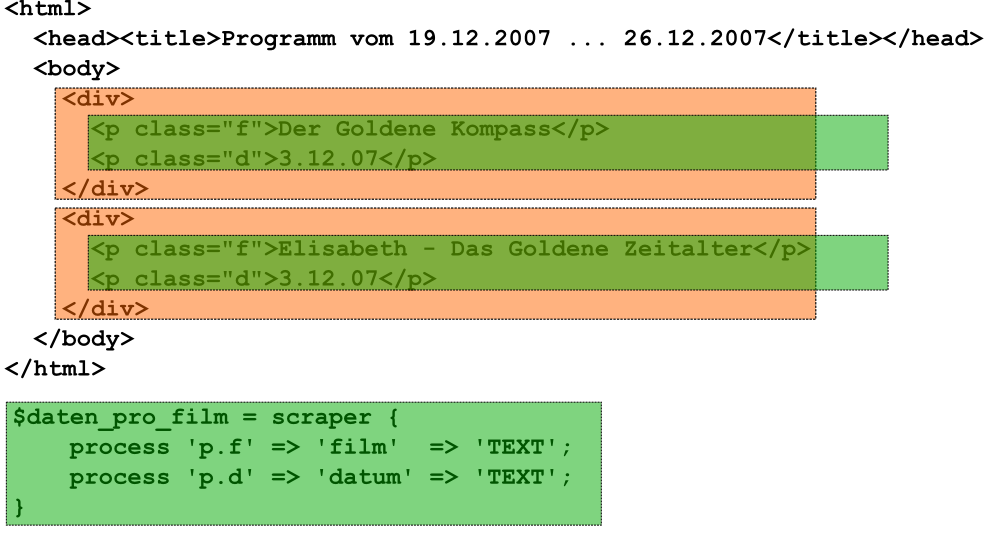
Schleifen mit Web::Scraper

Schleifen mit Web::Scraper
Bonusprogramm

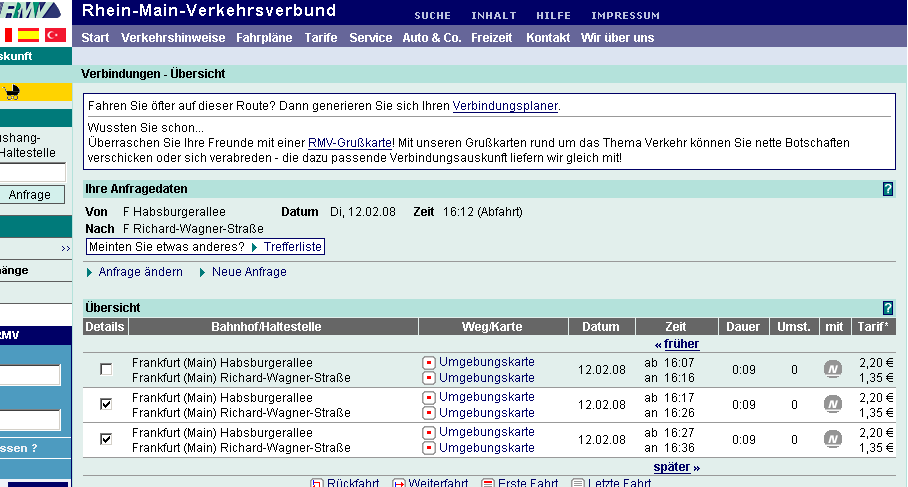
Extraktion aus RMV.de
Abfahrtszeiten und Fahrtstrecken
Ergebnis-Seite