Perl f³r Fortgeschrittene
Max Maischein
Frankfurt.pm
Perl f³r Fortgeschrittene
Was zeichnet einen fortgeschrittenen Perl Programmierer aus? (Nathan Torkington)
-
Novize: Perl und CGI sind das selbe
-
Initiierter: Denkt, Perl sollte mehr wie Java sein
-
Anwender: Kennt und nutzt CPAN, verwendet
<DATA> -
Adept: Verwendet
s///e, schreibt eigene Module in Perl -
Hacker: Verwendet
AUTOLOAD -
Guru: Kann alles mit Perl schreiben, und tut es
-
Zauberer: Schreibt keine Spiele in Perl, da Perl das Spiel ist
Perl f³r Fortgeschrittene
Was zeichnet einen fortgeschrittenen Perl Programmierer aus? (Nathan Torkington)
-
Novize: Perl und CGI sind das selbe
-
Initiierter: Denkt, Perl sollte mehr wie Java sein
-
Anwender: Kennt und nutzt CPAN, verwendet
<DATA> -
Adept: Verwendet
s///e, schreibt eigene Module in Perl -
Hacker: Verwendet
AUTOLOAD -
Guru: Kann alles mit Perl schreiben, und tut es
-
Zauberer: Schreibt keine Spiele in Perl, da Perl das Spiel ist
Motivation
-
Zu wenig Zeit
-
Zwei Projekte in einem, RemoteDownload und Vortrag
-
"interessante" Stellen des Codes schauen wir genauer an
Projekt RemoteDownload
1: HTTP POST HTTP 2: +---------+ +---------+ +-----------+ 3: | Client | ------> | Mein | -----> | Webserver | 4: | | | Server | | | 5: | | <------ | | <----- | | 6: +---------+ +---------+ +-----------+ 7: Nachricht Datei
-
Client: FireFox mit URL-POST Plugin (selbstgeschrieben)
-
Server: CGI bzw.
HTTP::Server::SimpleServer zum Testen -
wgetzum Download -
Einfaches HTML f³r die Fortschrittsanzeige
Zusõtzlicher Kram
-
Programme zum Start (Server und CGI, in
bin/) -
Tests f³r die einzelnen Module (
t/) -
Downloadverzeichnis (
downloads/) -
Templates f³r das HTML (
templates/)
Namen
Anwendungsname: App::RemoteDownload
-
App::RemoteDownload::CGI- CGI / HTML Darstellung -
App::RemoteDownload::Job- ein einzelnes Download -
App::RemoteDownload::Queue- die Warteschlange -
HTTP::Server::RemoteDownload- ein kleiner Testserver -
WWW::Wget- Kapselung vonwget
Frameworks und Bibliotheken
-
You call a library
-
A framework calls you
-
Gut, wenn das Framework meinen Code aufruft, wann ich es will
-
Meistens schlecht, weil das Framework entweder meinen Code gar nicht aufruft
-
... oder ich die Stelle nicht finde, an die ich meinen Code schreiben muss
Frameworks
-
Frameworks sind mõchtig
-
... aber sie behindern uns beim Verstõndnis, was sie eigentlich tun
-
Daher: Keine Frameworks, sondern alles in Handarbeit oder mit Bibliotheken
-
Das ist zwar nicht immer effizient (Templates), aber erstaunlicherweise klappt es f³r Webserver extrem gut.
-
Auch bei
DBIx::Classkõmpfe ich oft mit der Konfiguration und der Flexibilitõt vonDBIx::Class -
F³r ein CPAN-Release bzw. Anbindung an andere Module ist dieser Ansatz nicht unbedingt zielf³hrend.
Referenzen und anonyme Datenstrukturen
Datentypen in Perl:
-
Scalar -
$- ein einzelnes Element -
Array -
@- eine geordnete Folge von Skalaren -
Hash -
%- eine ungeordnete Menge von Paaren (String,Skalar) -
Codereferenz -
&- Code -
Glob -
*- ein Eintrag eines globalen Namens -
Format
Referenzen
Eine Referenz ist immer ein Skalar
Referenzen sind wie eine Schnur - man zieht an einem Ende und hat den Wert am anderen Ende
Bessere Metaphern sind willkommen
Referenzen: Skalare
1: my $bird = "Woodstock"; 2: my $piepmatz = \$bird; 3: 4: print $bird; # Woodstock 5: print $$piepmatz; # Woodstock
Vorsicht beim ─ndern von referenzierten Werten:
1: $$piepmatz = "Polly"; 2: print $bird; # Polly
Sehr gut zum gemeinsamen (Schreib-)Zugriff auf Werte. Sehr schlecht, wenn doch nicht alles geteilt werden sollte.
Referenzen erzeugen
Einen anonymen Skalar zu erzeugt man durch direktes Nehmen der Referenz:
1: my $bird = "Woodstock"; 2: my $piepmatz = \"Woodstock"; 3: 4: print $bird; # Woodstock 5: 6: print $piepmatz; # SCALAR(0x1822c34) 7: 8: print $$piepmatz; # Woodstock
Referenzen: Arrays
[] erzeugt ein Array
1: my @cats = ('Tom','Garfield','Hobbes');
2: my $katzen = ['Tom','Garfield','Hobbes'];
3:
4: @cats
5: @{ $katzen }
6:
7: print $cats[0]; # Tom
8: print $katzen->[1]; # Garfield
Referenzen: Hashes
{} erzeugt ein Hash
1: my %animals = ( 2: dogs => [ 'Snoopy', '' ], 3: cats => \@cats, 4: );
1: my $tiere = {
2: hunde => [ 'Snoopy', '' ],
3: #katzen => \@{$katzen},
4: katzen => $katzen,
5: };
Referenzen: Code
sub erzeugt anonymen Code.
Wird ³berall verwendet:
1: sort, grep, map
2:
3: my @files = grep { -f } readdir DIR;
4:
5: my @files = grep sub { -f $_ }, readdir DIR;
Codereferenzen
1: sub hello { print "Hello" };
2: my $sag_hallo = sub { print "Hallo" };
3:
4: hello(); # Hello
5: $sag_hallo->(); # "Hallo"
6:
7: my $greet = $lang eq 'de' ? $sag_hallo : \&hello;
8: $greet->();
9: # "Hallo" oder "Hello",
10: # abhõngig von der Sprache
Eigenes grep schreiben
1: sub my_grep (&@) {
2: my $code = shift;
3: my @result;
4: for (@_) {
5: if ($code->()) {
6: push @result, $_;
7: }
8: }
9: @_
10: }
Symbolische Referenzen
Symbolische Referenzen sind Schn³re mit Namen
1: $var = 'hallo'; 2: @$var entspricht @hallo
-
B÷se!
-
B÷se!
-
BųSE!
Alternative zu symbolischen Referenzen
1: %user_variables = (
2: hallo => [],
3: );
4: $user_variables{hello}->[0] = 'World';
Objekte, Closures
Die Queue ist in einer Datenbank (SQLite).
Ich schreibe aber ungern das simple SQL (INSERT, UPDATE, SELECT).
Ein eigener ORM (Object Relational Mapper)
Nachbau von Class::DBI bzw. DBIx::Class, aber auf uns
zugeschnitten, und weniger flexibel.
ORM
Tabelle:
1: job_id | url | destination 2: ----------+------------------+------------- 3: 666 | http://google.de | index.html 4: ...
Perl Struktur
1: { job_id => 666,
2: url => 'http://google.de',
3: destination => 'index.html' }
ORM
Statt selber das SQL zu schreiben, m÷chte ich transparent direkt inder Datenbank õndern.
Das ist ineffizient. Na und?
1: print $job->url(); # http://google.de
2: $job->url("http://www.perlworkshop.de");
3: $job->update(); # Schreibt alle Werte in die Datenbank
Die Routinen f³r die Spalten sollen (halb)automatisch erzeugt werden.
Sichtbarkeit und Lebensdauer
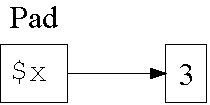
my erzeugt eine lexikalische Bindung ("binding")
eines Namens an einen Wert:
1: my $x = 3;
Eine Bindung besteht nur innerhalb des Sichtbarkeitsbereichs. Perl speichert die aktuell g³ltigen Bindungen in einer speziellen Datenstruktur, dem "Pad".
use strict; hilft, bei lexikalischen
(my) und globalen (use vars;) Variablen
die Bindungen zu ³berpr³fen.
Sichtbarkeit im Quellcode
Sichtbarkeit hõngt nur vom Quellcode ab:
-
Klar bei globalen Variablen
-
Auch klar bei lexikalischen Variablen
sub foo {
...;
...
Lebensdauer von Werten
Lebensdauer von Werten und Sichtbarkeit von Bindungen sind nicht das selbe.
Datenstruktur in Zeile 4:
1: my $x;
2: {
3: $x = 3;
4: my $r = \$x;
5: }
Hier stimmen Lebensdauer und Sichtbarkeit ³berein.
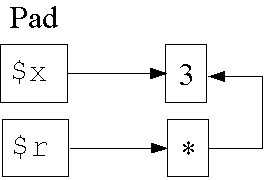
Lebensdauer von Werten (I/2)
Datenstruktur in Zeile 5 (Zwischenschritt):
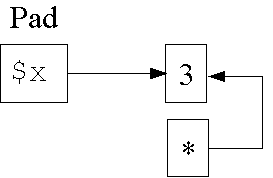
1: my $x;
2: {
3: $x = 3;
4: my $r = \$x;
5: }
Lebensdauer von Werten (I/3)
Datenstruktur in Zeile 5:
1: my $x;
2: {
3: $x = 3;
4: my $r = \$x;
5: }
Lebensdauer von Werten (II/1)
Datenstruktur in Zeile 4:
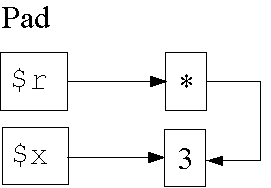
1: my $r;
2: {
3: my $x = 3";
4: $r = \$x;
5: }
Lebensdauer von Werten (II/2)
Datenstruktur in Zeile 5:
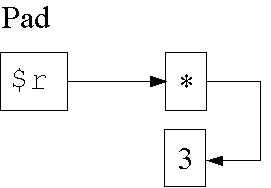
1: my $r;
2: {
3: my $x = 3";
4: $r = \$x;
5: }
Verwendung mit Objekten
1: my %self = ...; 2: return bless \%self, $class;
-
Geht nicht mit C!
-
Auto-Variable (bzw. Variable auf dem Stack) d³rfen nicht nach dem
returnverwendet werden. -
In C:
malloc/new/free
Verwendung als Zõhler
1: sub make_counter {
2: my $pos = shift || 1;
3: return sub {
4: $pos++
5: }
6: };
7:
8: my $c1 = make_counter;
9: my $c2 = make_counter(10);
10: print $c1->(); # 1
11: print $c2->(); # 10
12: print $c1->(); # 2
13: print $c2->(); # 11
ORM
Statt selber das SQL zu schreiben, m÷chte ich transparent direkt in der Datenbank õndern.
Das ist ineffizient. Na und?
1: print $job->url(); # http://google.de
2: $job->url("http://www.perlworkshop.de");
3: $job->update(); # Schreibt alle Werte in die Datenbank
Die Routinen f³r die Spalten sollen (halb)automatisch erzeugt werden.
Accessors als Closures
1: package RemoteDownload::Job; 2: 3: @columns = (qw(job_id owner 4: pid url destination status position)); 5: 6: __PACKAGE__->mk_accessor($_) for (@columns);
Accessors ³ber eval
1: sub mk_accessor {
2: my ($class,$name) = @_;
3: eval <<CODE;
4: sub $class\::$name {
5: if (\@_ == 1) {
6: \$_[0]->{$name}
7: } else {
8: \$_[0]->{$name} = \$_[1]
9: };
10: };
11: CODE
Hõ▀lich, da Syntaxfehler im eval gesondert
abgefangen werden m³ssen.
Die richtigen Variablen m³ssen gequoted werden, aber nicht alle!
Ausserdem ist die Stringform von eval nicht (so) performant
und grundsõtzlich gefõhrlich.
Accessors als Closures
1: sub mk_accessor {
2: my ($class,$name) = @_;
3: my $accessor = sub {
4: if (@_ == 1) {
5: $_[0]->{$name}
6: } else {
7: $_[0]->{$name} = $_[1]
8: };
9: };
10:
11: # Accessor installieren
12: no strict 'refs';
13: *{"$class\::$name"} = $accessor;
14: };
Verwendung einer Closure als $accessor.
Die Accessoren
1: my $job =
2: App::RemoteDownload::Job
3: ->find( job_id => 666 );
4: # SELECT @columns FROM queue
5: # WHERE job_id = 666
6: print $job->url();
7:
8: ...
9:
10: $job->update();
11: # UPDATE queue SET @columns = @{$self}{@columns}
12: $job->delete();
13: # DELETE FROM queue WHERE job_id = $self->{job_id}
Vergleich mit anderen ORMs
-
Wenig Konfiguration,
$dbhin globaler Variable, Tabellenname fest -
Wenig Flexibilitõt (nur eine Datenbankverbindung)
-
Wenig Code, wenig Abhõngigkeiten
-
Verkn³pfungen ³ber Tabellen habe ich weggelassen, weil ich sie hier nicht gebraucht habe
-
Siehe
SQL::Abstract,DBIx::Class,Class::DBI,Rose::Object
Verkn³pfungen von Tabellen
Die Verkn³pfungen ³ber Tabellen hinweg als Perl-Objekte
sind mit der Methode, wie sie in ->mk_accessor
genommen wurde, ebenfalls m÷glich:
1: sub has_many {
2: my ($class,$what,$how) = @_;
3: *{"$class\::$what"} = sub {
4: ...
5: };
6: };
Queue SQL
Das SQL f³r die Job-Queue, um den nõchsten freien Job zu belegen:
1: my $sth_lock = $self->dbh->prepare(<<""); 2: UPDATE queue SET pid = ? 3: WHERE job_id IN ( 4: SELECT job_id FROM queue WHERE 5: pid IS NULL 6: AND status IS NULL 7: LIMIT $count 8: )
1: if ($sth_lock->execute($$) > 0) {
2: $sth_lock->finish;
3: my $sth_items = $self->dbh->prepare(<<"");
4: SELECT job_id FROM queue
5: WHERE pid = ?
6: AND status IS NULL
7: ...
Das Webinterface
Implementiert ³ber HTTP::Server::Simple f³r das lokale Testen oder
als CGI Programm
f³r den Einsatz innerhalb eines anderen Servers.
HTTP::Server::Simple bzw. HTTP::Server::RemoteDownload ruft einfach den
zentralen Handler in App::RemoteDownload::CGI auf.
1: Browser 2: -> Server (Apache+CGI oder H:S:S) 3: -> App::RemoteDownload::CGI->handle_request() 4: -> Antwort (HTML)
Alle Anfragen laufen durch handle_request durch.
URLs mappen
Die URLs sollen irgendwie auf Code und Templates passen:
-
^/$-> Willkommensseite, GET -
^/submit$-> Neues Download abgeben (User ³ber.htaccess, URL als Parameter, POST) -
^/remove/(.*)$-> Download l÷schen (User ³ber.htaccess, JobID als Parameter, POST) -
^/list$-> Liste f³r einen User anzeigen (User ³ber.htaccess, GET)
Dispatch ³ber if
1: sub App::RemoteDownload::CGI::handle_request {
2: my ($self,$cgi) = @_;
3:
4: my $p = $cgi->query_path;
5: if ($p =~ m!^/!) {
6: $self->index();
7: } elsif ($p =~ m!^/submit!) {
8: ...
9: }
10: }
Schwer zu warten und zu konfigurieren.
Dispatch Tabellen
Idee: Wir speichern die Zuordnung von URL bzw. regulõrem Ausdruck zu der behandelnden Subroutine in einem Hash:
1: %handler = ( 2: '^/$' => 'init', 3: '^/submit$' => \&handle_submit, 4: '^/remove/(.*)$' => \&handle_remove, 5: '^/list$' => \&handle_list, 6: );
▄bersichtlicher zu warten und zu konfigurieren. Das Programm hat auch Zugriff auf alle g³ltigen URLs und kann diese zur Diagnose oder als Navigationsbalken auch ausgeben.
handle_request
1: sub handle_request {
2: my ($self,$cgi) = @_;
1: my $p = $cgi->path_info;
2: for my $spec (keys %urls) {
3: if ($p =~ /$spec/) {
4: # Pfad-Parameter extrahieren
5: my @args = $p =~ /$spec/;
1: my $method = $urls{$spec};
2: $self->$method(query => $cgi,
3: args => \@args);
4: return;
5: };
6: };
7:
8: # ansonsten auf die Startseite
9: print $cgi->redirect('/');
10: };
Ausgabe in HTML
Meine eigene Templating Engine
Darstellung der Job-Queue f³r einen User:
1: job_id url status 2: ...
Erste L÷sung - direkte Stringausgabe
1: print "<html>...</html>";
Templates (CPAN)
Zweite L÷sung - CPAN Module
Templates ³ber HTML::Template, Template Toolkit etc.
Templates (Eigene Engine)
Dritte L÷sung - die eigene Templating Engine:
Syntax:
1: $user # $user
2: $hash.key # $hash->{key}
Listen
1: [% START jobs %] 2: $job_id | $url | $status 3: [% END jobs %]
(Die Listensyntax ist geklaut von Template::Simple)
Implementation
Der erste Ansatz kann nur einfache Variablensubstitution
1: sub process {
2: my ($template,$parameters) = @_;
3: my $result = $template;
4:
5: $result =~ s{\$(\w+)}{
6: $parameters->{$1}
7: }mge;
8: }
1: process('Hallo $name', {name => 'Max'});
2: # "Hallo Max"
Daf³r extrem kurz.
s///ge
s/A/B/ge sucht A, und f³hrt dann B als Perl Code aus.
1: "123" =~ s/(\d)/$1+1/ge; # 234
1: # Variablenersetzung
2: %parameters = (
3: greeting => 'Hallo',
4: user => 'Erdling',
5: );
6: '$greeting $user' =~ s/\$(\w+)/$parameters{$1}/ge;
7: # "Hallo Erdling"
Implementation (2)
Ab hier wird's kompliziert (und ungetestet) - ich empfehle f³r
solche komplizierteren Fõlle Template::Toolkit oder õhnliches.
Kann auch Pfade in Hashes
1: sub process {
2: my ($template,$parameters) = @_;
3: my $result = $template;
4:
5: $result =~ s{\$(\w[\w.]+)]}{
6: dive($1,$parameters)
7: }mge;
8: }
1: process('Hallo $user.name',
2: { user => {name => 'Max', id => 666}});
3: # "Hallo Max"
Implementation
Es fehlt noch das Aufsuchen des Pfades in dem Hash:
1: sub dive {
2: my ($path,$parameters) = @_;
3: my @elems = split /\./, $path;
4: my $val = $parameters;
5: for (@elems) {
6: $val = $val->{$_};
7: }
8: $val
9: }
Implementation
Jetzt fehlen noch wiederholende Listen:
1: # Schon wieder eine Dispatchtabelle
2: my %handler = (
3: 'HASH' => \&dive,
4: 'SCALAR' => sub { $_[1] },
5: 'ARRAY' => \&render_repeat,
6: );
1: sub render_repeat {
2: my $tmpl = shift;
3: my $name = shift;
4: my $params = shift;
5: @_ = $params->{$name};
6: join '', map { process( $tmpl, $_ )} @_ },
7: }
Wiederholende Listen
1: sub process_repeat {
2: my ($template,$parameters) = @_;
3: my $result = $template;
4:
5: s{[% START (\w+) %](.*?)[% END \1 %]}
6: {render_repeat($2,$1,$parameters)}ge;
7: $result;
8: }
Kombiniert
1: sub process {
2: my ($template,$parameters) = @_;
3: my $result = $template;
4:
5: s{[%\s*START\s*(\w+)\s*%](.*?)[%\s*END\s*\1\s*%]
6: |
7: \$([\w.]+)
8: }
9: {
10: process_item($2, $1||$3, $parameters }
11: }gsex;
12: $result;
13: }
Kombiniert (2)
1: sub process_item {
2: my ($template,$name,$parameters) = @_;
3: my $val = $parameters->{$name};
4: $handler{ref $val}->($template, $val);
5: }
Ist das sinnvoll?
Wenn man eine volle Templating Engine mit Listenverarbeitung, Bedingungen etc. braucht, ist es nicht unbedingt sinnvoll, diese selber zu implementieren.
Aber die einfachste aller Templating Engines ist in sehr vielen Sprachen verf³gbar (JavaScript, Python, ...) und schnell selber geschrieben.
Siehe auch
-
HTML::Template,HTML::Template::Compiled -
Template::Toolkit -
HTML::Mason -
Template::Simple
Tests von erweiterter IPC
WWW::Wget verwendet den selben Mechanismus wie Source::FFmpeg zum starten eines externen Programms und ³berwachen des Status:
1: sub spawn {
2: my ($self,@cmd) = @_;
3: my $wget;
4: $self->{pid} = open $wget, '-|', @cmd
5: or die "Couldn't spawn [@cmd]: $! / $?";
6: return $wget
7: };
WWW::Wget
1: sub get {
2: ...
3: my $wget = $self->spawn(...);
4: ...
5: while (<$wget>) {
6: ...
7: }
8: }
... aber wie wollen wir das Testen?
Testen von erweiterter IPC
-
Testen mittels Request zu
http://google.de(Live-Test) -
Schreiben eines eigenen
fake-wget -
Ersetzen von
->spawn()durch unseren eigenen Code
Das Testprogramm (Setup)
1: use Test::More tests => 4;
2:
3: use_ok 'WWW::Wget';
4:
5: {
6: no warnings 'redefine';
7: *WWW::Wget::spawn = sub {
8: return \*DATA;
9: };
10: };
Das Testprogramm (Durchf³hrung)
1: my @bytes;
2: my $wget = WWW::Wget->new(
3: on_bytes => sub { push @bytes, $_[1] }
4: );
5: isa_ok $wget, 'WWW::Wget';
6: my $saved_as = $wget->get('test://url');
7: cmp_ok $saved_as, "eq", "162.18_forceware_winxp_international_whql.exe.2", "Guessed the right save filename";
8: is_deeply \@bytes, [384*1024, 786432,1179648,1572864,1966080,2359296,2752512,3145728,3538944,3932160,4325376,4718592],
9: "The callbacks were called OK";
Das Testprogramm (Die Daten)
1: __DATA__ 2: --16:04:14-- http://de.download.nvidia.com/Windows/162.18/162.18_forceware_winxp_international_whql.exe 3: => `162.18_forceware_winxp_international_whql.exe.2' 4: Resolving de.download.nvidia.com... done. 5: Connecting to de.download.nvidia.com[84.53.134.241]:80... connected. 6: HTTP request sent, awaiting response... 200 OK 7: Length: 71,609,184 [application/octet-stream] 8: 9: 0K ................ ................ ................ 0% 793.39 KB/s
Ersetzen von anderen Subroutinen
1: sub greet { print "Hallo" };
2: sub output_greeting {
3: greet;
4: print $session->user;
5: }
6: {
7: # Wir m³ssen HTML ausgeben
8: no warnings 'redefine';
9: local *greet = sub {
10: print "<b>Hallo</b>";
11: };
12: output_greeting;
13: # <b>Hallo</b> Max
14: }
15: output_greeting;
16: # Hallo Max
Zusammenfassung
Was haben wir gesehen?
-
Referenzen und Speicherverwaltung von Perl
-
Closures
-
Erzeugen von Subroutinen/Methoden ohne
eval -
Dispatchtabellen (URL-Regex => Code)
-
Temporõres Ersetzen von Code mit anderem Code (Tests)
Danke
Fragen?